#12 Adding Phenotypes and Datastores to Trellis
This week I’ll be discussing updates to the Trellis Neo4j metadata store as well as methods for interacting for our other database, the PostgreSQL CloudSQL instance where sample level quality control metrics are stored.
Adding phenotype information to Trellis
As part of our effort to estimate telomere length, we want to measure the correlation between telomere length and age as well as potentially other phenotypes such as Abdominal Aortic Aneurysm (AAA). To faciliate these kinds of analysis, I wanted to establish a model for adding phenotypes to the Trellis Neo4j metadata store. Our existing Neo4j graph model is focussed primarily on tracking data provenance, so incorporating phenotype information was a new challenge. Read about it on the Trellis ReadTheDocs as well as the solution I adopted.
Querying sample level quality control metrics
Another question that came up in the context of telomeres, was whether the read length of our sequencing data was uniform across all samples. We already use FastQC to calculate read length, but that information was somewhat buried in the PostgreSQL CloudSQL instance we use track sample level quality control metrics generated by FastQC, Samtools Flagstat, and rtgtools Vcfstats. See this GitHub issue to find out how to interact with the database and run SQL queries. For those of you only interested in the results, all our samples have reads of sequence length 150.
Tracking datastores in Neo4j
In addition to being able to independently interact with the quality control database, I also want to better track where this data is stored in our Neo4j metadata store. Right now the change of provenace ends at the point where an individual sample quality control object is transformed from structure text to table format. But the process of loading that CSV object into the database is not stored in the graph. This makes it more difficult for naive uses to:
- Recognize that quality control metrics are aggregated and stored in a queryable SQL database.
- Know where the database lives, how to connect to it, and what kind of schema it uses so they can understand how to interact with it. 3
You can follow along as I document this effort in this GitHub issue.
Tracking database loading operations in Neo4j
Another crucial reason to track these database operations in Neo4j is so that we have better visibility into which data has been added to the quality control database. Right now a significant bottleneck in releasing whole genome sequencing data is that we are missing quality control data for 1000s of samples.
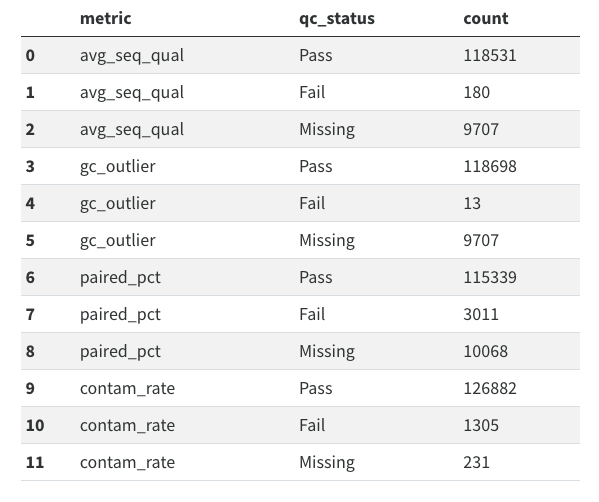
I hope that adopting a better design pattern for tracking database loading operations will also illucidate where and why we are losing quality control data.
Discuss
Discuss this blog post on our GitHub!